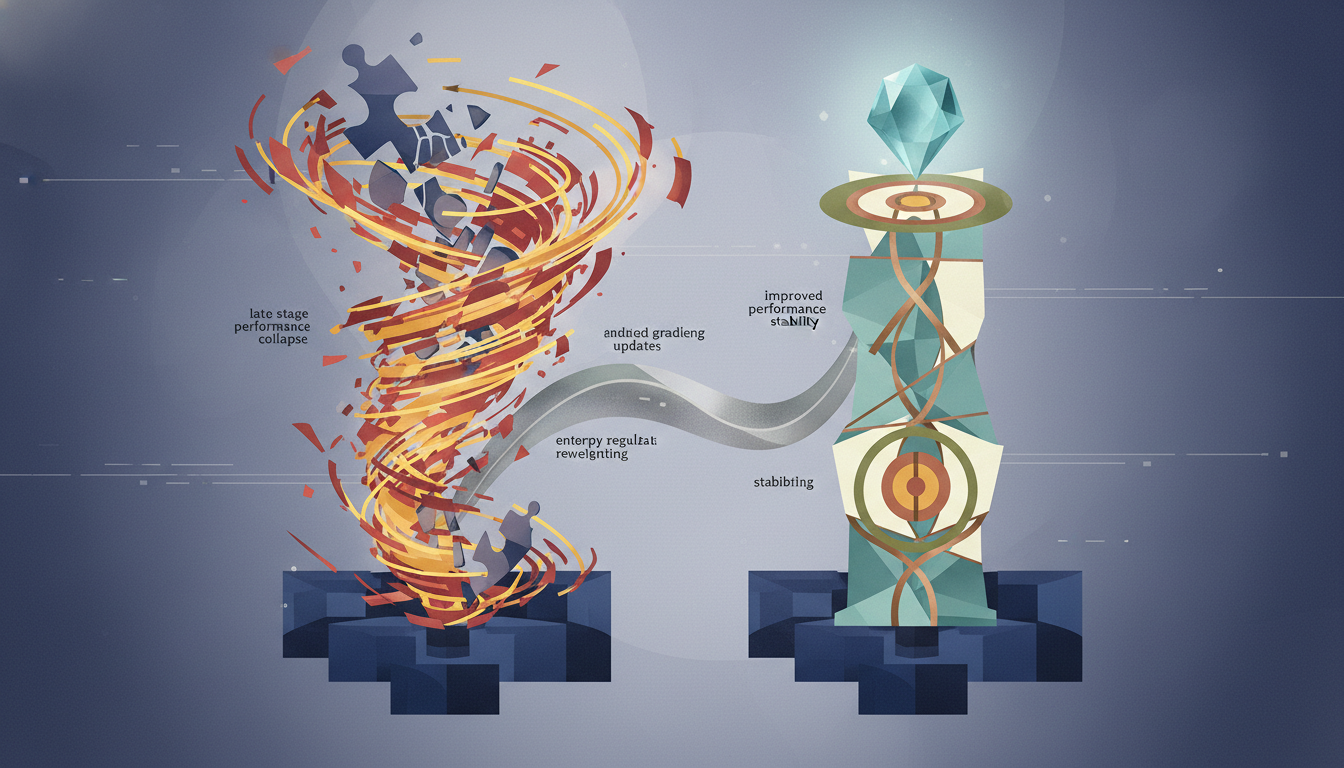
According to arxiv.org, researchers have identified a critical stability problem in reinforcement learning (RL) for large language models: a small fraction of tokens, termed “spurious tokens” (around 0.01%), contribute little to reasoning outcomes but receive disproportionately amplified gradient updates. These tokens inherit full sequence-level rewards, leading to what the paper describes as “late-stage performance collapse” and “degraded reasoning quality and unstable training.”
The research team, led by Shiqi Liu and colleagues, presented STAPO (Stabilizing Reinforcement Learning for LLMs by Silencing), published in May 2026. According to the arxiv.org abstract, the method addresses how “existing RL fine-tuning methods rely heavily on heuristic techniques such as entropy regularization and reweighting to maintain stability.”
In related work published the same week, another study documented a phenomenon called “Causal Tongue-Tie,” where LLMs encode correct causal understanding internally but fail to express it verbally. According to arxiv.org, “a fixed linear probe recovers the evidence-supported answer from the model’s hidden state (accuracy approximately 0.97), while the spoken Yes/No reverts to the commonsense one (accuracy approximately 0.5).”
Additionally, researchers proposed Implicit Behavior Policy Optimization (IBPO) to address credit-assignment problems in multi-step reasoning, according to arxiv.org, using “counterfactual-comparison” to convert sparse terminal rewards into “step-sensitive learning signals.”